
Exploring a Domain-Specific AI Agent for CALS Investment Manager
At CALS OIT, the Administrative Computing team plays a vital role in supporting the college’s operations through building and maintaining custom applications tailored to the unique needs of different groups in our college.
One of those applications is CIM, or CALS Investment Manager, developed for the Office of Budget and Finance, which is responsible for managing the entire college budget. This system is used to manage the college’s endowment, a crucial piece of our financial planning and budget.
The Challenge
CIM already delivers all the functionality needed for the budget office’s operations, but I was curious whether an embedded AI assistant, designed specifically for this application, could help users work more effectively. Through a series of interviews with stakeholders, I identified three areas that were worth exploring:
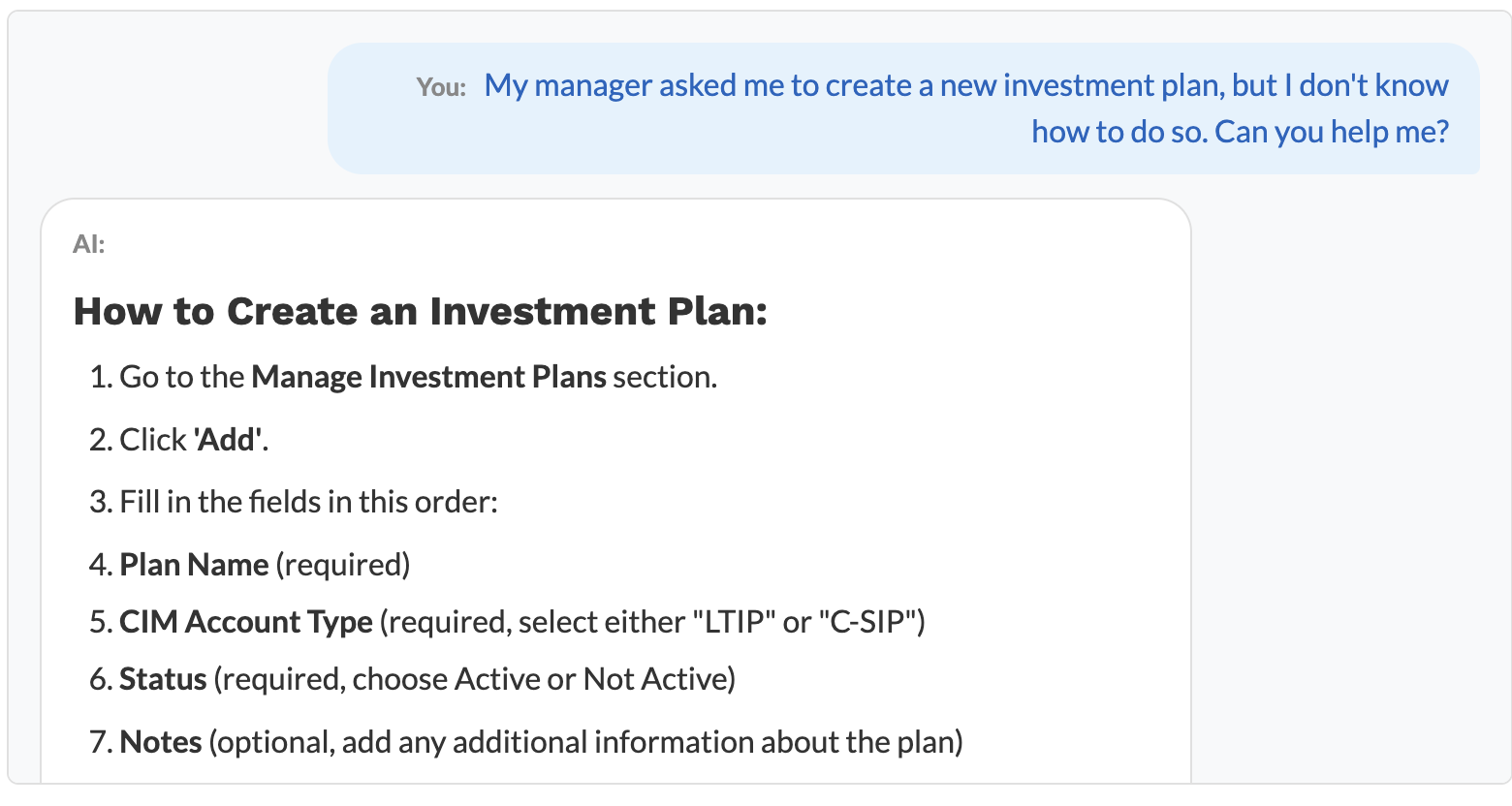
1. In-App “How To” Guidance
A system to help onboard and support users as they go, giving step-by-step instructions for tasks inside CIM.
2. Data Entry Validation and Error Reduction
Flagging potential issues in entered data and suggesting ways to correct them, keeping final approval in the user’s hands.

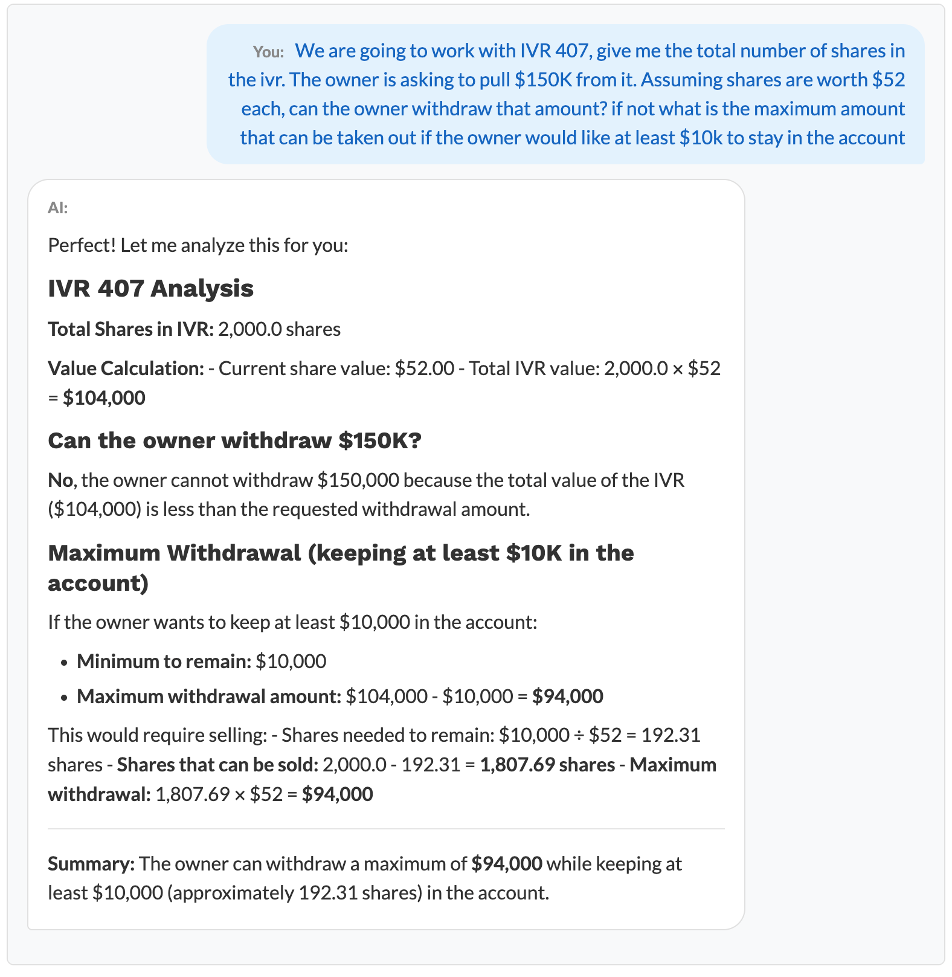
3. Answering Complex Data Questions
Fetching and summarizing information from CIM quickly, allowing the budget office to receive accurate answers without navigating multiple reports or manually digging through data.
To demonstrate this capability, I created a hypothetical account containing a mock investment. This example below does not involve real institutional data, actual users, or any real financial figures. The AI correctly applied the limitations I specified when evaluating the mock investment and provided an advisory response to the request.
This led to the creation of an application-specific AI agent that:
- Knows CIM’s functions and data models.
- Supports everyday tasks like onboarding, troubleshooting, and data analysis.
- Never strays into unrelated topics or generalized “chatbot” territory.
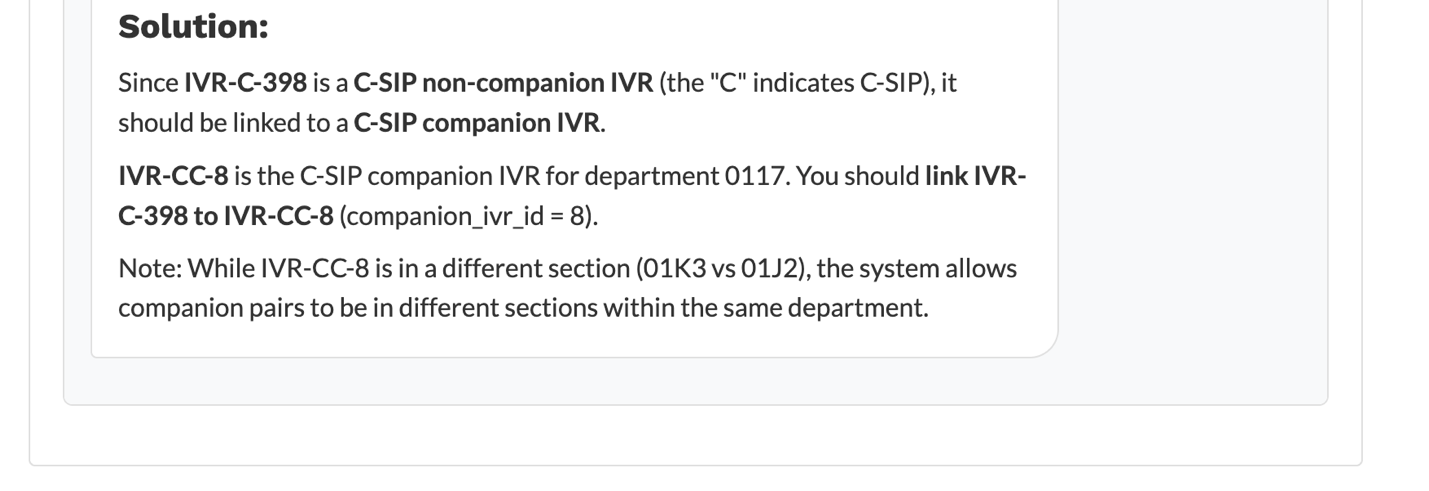
But one deeper challenge emerged: business rules aren’t always in the data. Many safeguards exist only in code logic. For example, certain account types can only interact with specific other account types. These rules are invisible to the AI, which only ‘sees’ tabular data, meaning it could give misleading suggestions. This is an important limitation that we, as developers, should be mindful of. We need to create innovative ways to address this gap between application data and institutional knowledge to ensure trust and accuracy.
Implementation Details
Designing the AI agent for CIM required connecting an LLM to data, but granting it unfiltered access to all the data in the system is neither secure nor efficient. I consulted with other members of the AI innovation lab to arrive at a better approach: a set of specialized tools.
These tools ensure deterministic answers, meaning that a similar question always produces the same result, even when users phrase their queries differently. For example, two users might ask the same question in completely different ways, but the AI will still fetch the same underlying data. Each tool acts as a gateway between the AI agent and the application’s data or knowledge, with a clearly defined purpose and strict usage parameters.
For example, a tool might be responsible for retrieving all investment records tied to a specific owner id (get_ivr_for_employee_id), but if the user provides a name instead of an employee id, the AI does not guess at the id – instead, it calls another tool (get_employee_id_by_name) to look up the proper identifier and either proceeds or notifies the user if no match is found. This modular approach gives the AI agent a concrete “vocabulary” for talking to the application. And because each tool is deterministic (supports only system-approved inputs), the output it produces remains consistent.
Handling “How To” guidance required a different strategy. An AI agent answering, “How do I do this action in CIM?” theoretically needs full insight into the application’s code or access to detailed documentation (a great potential for a Confluence Model Context Protocol). Sending the entire code base to the LLM is unrealistic, so to work around this, I used Cline, connected to the Cornell AI Gateway, to review CIM’s code base and to compile instructions, rules, and procedural steps that cover common user actions. The Gateway was then instructed to transform these into static “knowledge base tools” that the AI agent can consult when responding to user onboarding and workflow questions. In effect, the AI draws on a pre-computed map of CIM’s functions rather than discovering them dynamically, which keeps it consistent but requires updates whenever the code or workflows change.
Both types of tools share a similar pathway; the LLM receives the user’s prompt, performs natural language parsing to identify what is being asked, and selects the most appropriate tool (or sequence of tools) to fulfill the request. In future development, I am hoping to allow the LLM to chain a larger number of tools together for multi-step questions, but for the time being, nested requests beyond two or three steps often exceed the iteration budget, meaning a request along the lines of “find the employee id of John Doe, pull all related account data, calculate investment returns, and determine available withdrawals” will likely fail. Instead, at least for now, users and the agent engage in back-and-forth conversations, breaking complex queries down into smaller parts.
This type of technical design has many benefits, including:
- Security – each action happens through predefined, permission-based functions. I can also limit the access to specific tools or outputs based on the person asking the question.
- Clarity – users receive consistent, repeatable results without “black box” behavior.
- Flexibility – tools can handle optional parameters, adapting to different ways people phrase requests.
Using tools involves trade-offs, however. Preloading all tools into the AI’s prompt can increase token usage and cost, which I am hoping to address via a dynamic tool search. Further, the reliance on static knowledge base tools requires disciplined updates. Finally, iteration limits mean that some deep, multi-step analyses still rely on human guidance to break tasks down.
Despite these limitations, this process has proven to be a robust way to give an AI agent domain-specific expertise in CIM. Over time, improvements like embedding institutional business rules directly into its reasoning, additional tools development, and implementation of conversation memory, could make the agent even more capable.
Security and Compliance
One final aspect that I had to keep in mind is the security of our data. All interactions are routed through the Cornell AI Gateway, a secure, private gateway to AI models which ensures Cornell’s private data is protected.
Moreover, the AI agent is strictly read-only. It can guide, validate, and analyze, but cannot alter data directly.
Lessons Learned
- Data alone aren’t enough; business rules must be integrated into AI reasoning to prevent misleading answers.
- Read-only architectures are a safe way to explore AI enhancements while preserving data integrity.
- Human oversight remains essential to catch errors and validate suggestions.
Next Steps
- Improving the user experience with richer chat features and complex Markdown-formatted responses.
- Optimizing context usage and token management for efficiency.
- Adding session history for more continuous conversations.
- Expanding governance with stronger role-based tool access controls.
- Enhancing accuracy by embedding institutional business rules into the AI’s decision-making layer
- Regular security reviews to ensure continued adherence to Cornell’s data safety requirements.
Conclusion
This experiment shows that a domain-specific read‑only AI agent can enhance user experience and speed up access to information in custom applications.
Ido Efrati is a Programming Analyst Specialist at Cornell’s CALS Office of Information Technology, where he has spent nine years designing and architecting custom software solutions. He currently develops and maintains systems that support the college’s diverse operations while expanding into innovative AI-driven tools that enhance efficiency, support complex applications, and help users make sense of intricate data.